데이터 상세
한국학중앙연구원_고문서 내용 분류 정보
이 데이터셋은 한국 전통 기록유산인 고문서를 체계적으로 분류하고 관리하기 위해 설계된 표준화된 분류체계 자료로서, 문서 유형별 세부 정보를 제공합니다. 각 항목은 코드, 한글 이름, 한자 이름, 중문 이름, 영문 이름, 그리고 해당 문서 유형에 속하는 건수로 구성되어 있으며, 문서의 성격과 발신 주체, 기능에 따라 계층적 구조(예: 01 → 0101 → 010101 등)로 코드정보를 제공하는 것이 특징입니다.
이 데이터는 한국학 연구, 고문서 디지털 아카이빙, 사료분류 자동화, 국가 기록유산 관리 정책 수립 등에서 활용 가치가 높으며, 한자·중문·영문 정보가 함께 수록되어 있어 다국어 기반 AI 학습용 데이터로도 활용이 가능합니다.
이 데이터는 한국학 연구, 고문서 디지털 아카이빙, 사료분류 자동화, 국가 기록유산 관리 정책 수립 등에서 활용 가치가 높으며, 한자·중문·영문 정보가 함께 수록되어 있어 다국어 기반 AI 학습용 데이터로도 활용이 가능합니다.
공공데이터활용지원센터는 공공데이터포털에 개방되는 3단계 이상의 오픈 포맷 파일데이터를 오픈 API(RestAPI 기반의 JSON/XML)로 자동변환하여 제공합니다.
오픈 API를 활용하기 위해서는 공공데이터포털 회원 가입 및 활용신청이 필요하며, 활용 관련 문의는 공공데이터활용지원센터로 연락주시기 바라며,
데이터 자체에 대한 문의는 아래 제공기관의 관리부서 전화번호로 연락주시기 바랍니다.
파일데이터는 로그인 없이 다운로드를 통해 이용하실 수 있습니다.
오픈 API를 활용하기 위해서는 공공데이터포털 회원 가입 및 활용신청이 필요하며, 활용 관련 문의는 공공데이터활용지원센터로 연락주시기 바라며,
데이터 자체에 대한 문의는 아래 제공기관의 관리부서 전화번호로 연락주시기 바랍니다.
파일데이터는 로그인 없이 다운로드를 통해 이용하실 수 있습니다.
다른 사용자들이 활용한 데이터
로그인하셔서 다른 사용자들이 활용한 데이터를 추천받아 보세요
파일데이터 정보
공공데이터활용지원센터는 공공데이터포털에 개방되는 3단계 이상의 오픈 포맷 파일데이터를 오픈 API(RestAPI 기반의 JSON/XML)로 자동변환하여 제공합니다.
오픈 API를 활용하기 위해서는 공공데이터포털 회원 가입 및 활용신청이 필요하며, 활용 관련 문의는 공공데이터활용지원센터로 연락주시기 바랍니다.
파일데이터는 로그인 없이 다운로드를 통해 이용하실 수 있습니다.
오픈 API를 활용하기 위해서는 공공데이터포털 회원 가입 및 활용신청이 필요하며, 활용 관련 문의는 공공데이터활용지원센터로 연락주시기 바랍니다.
파일데이터는 로그인 없이 다운로드를 통해 이용하실 수 있습니다.
다른 사용자들이 활용한 데이터
로그인하셔서 다른 사용자들이 활용한 데이터를 추천받아 보세요
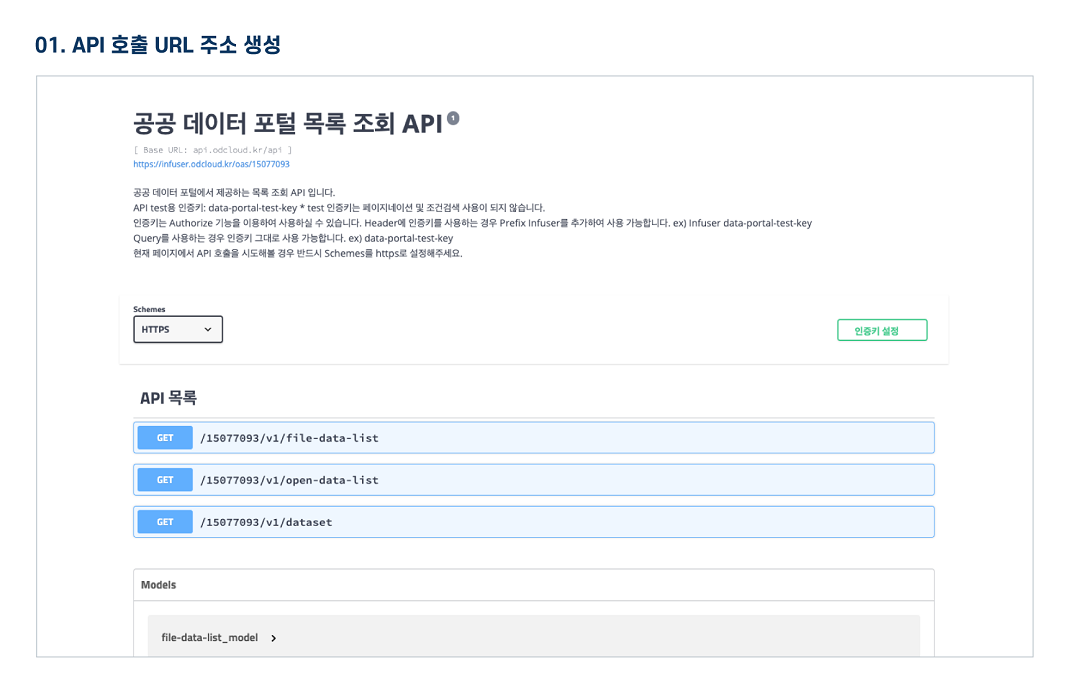
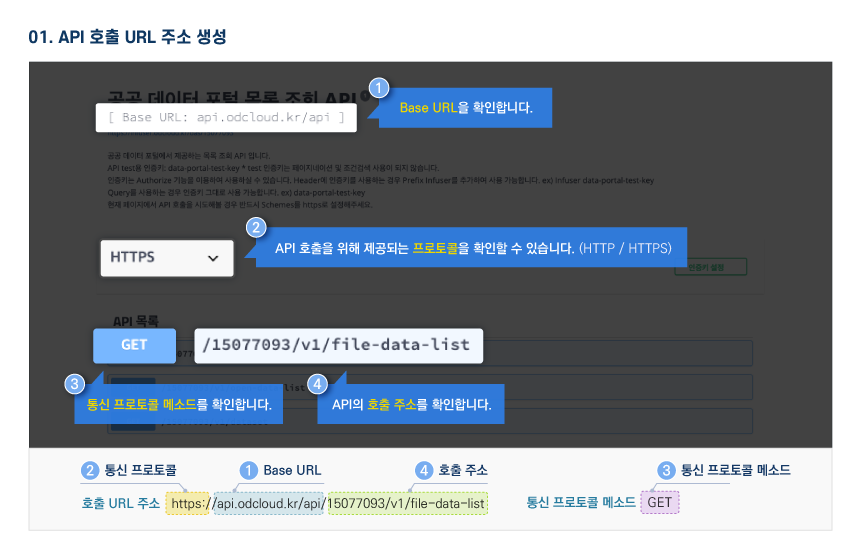
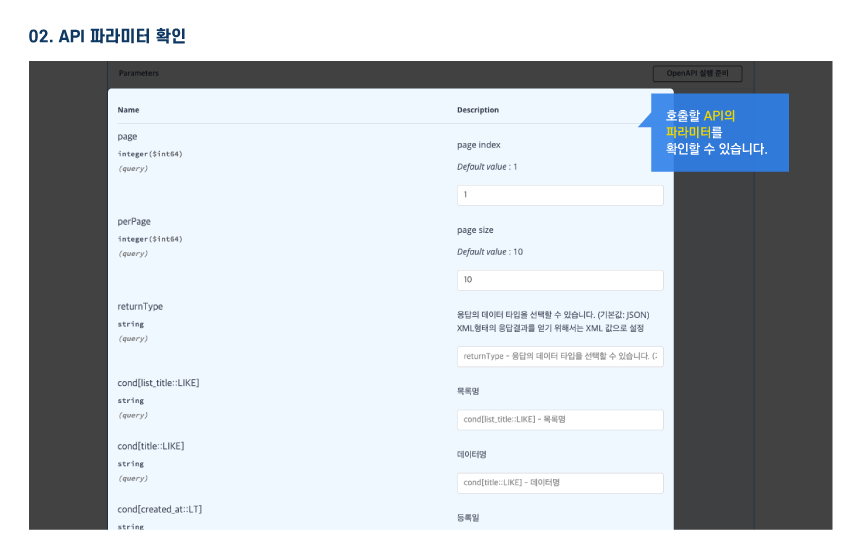
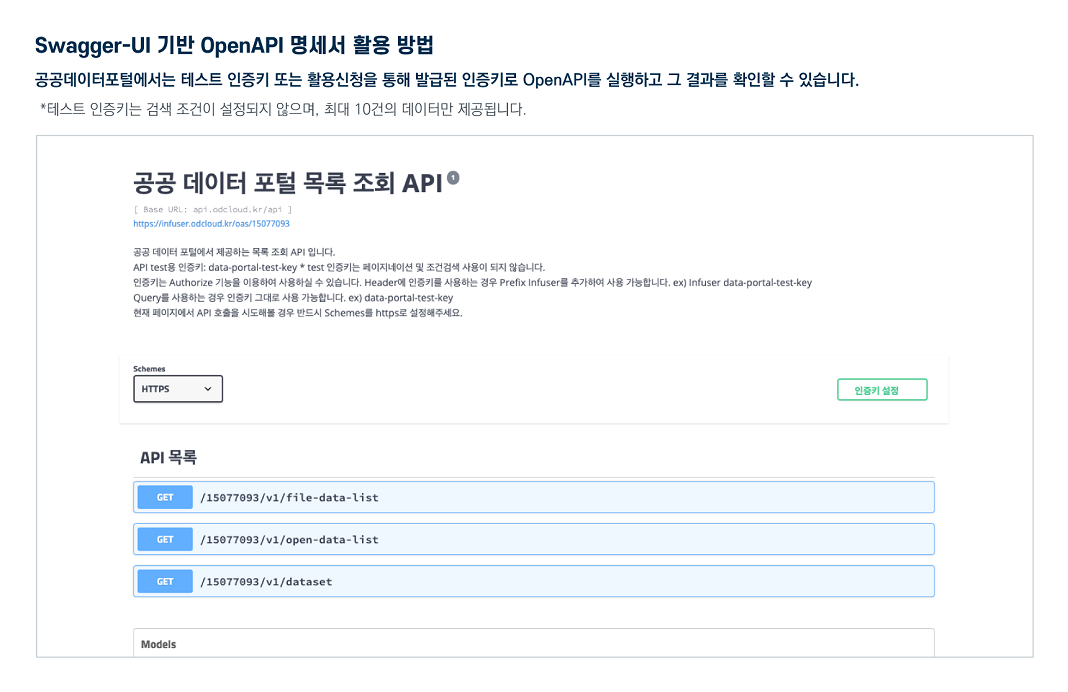
오픈API 정보
활용 명세

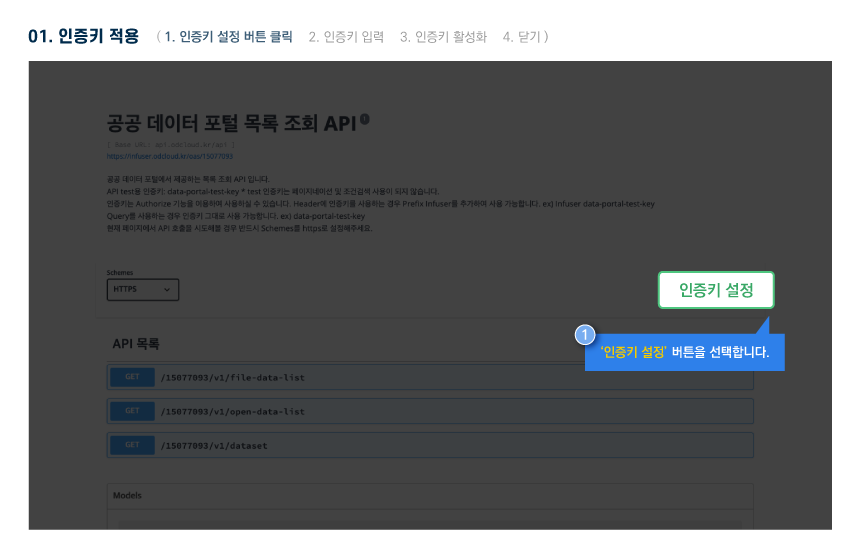
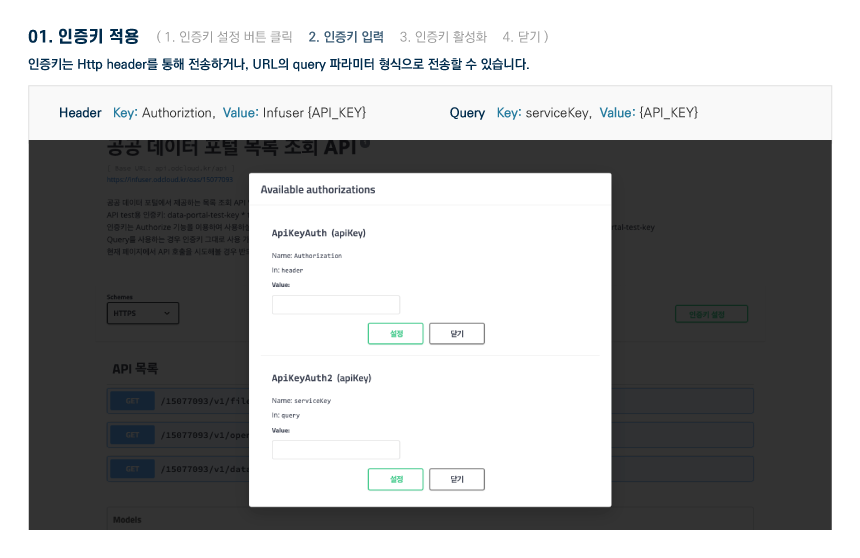
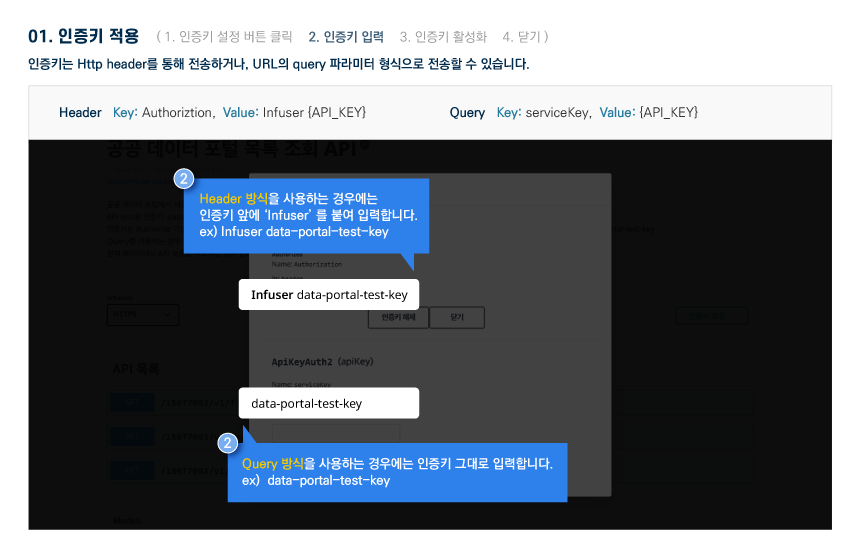
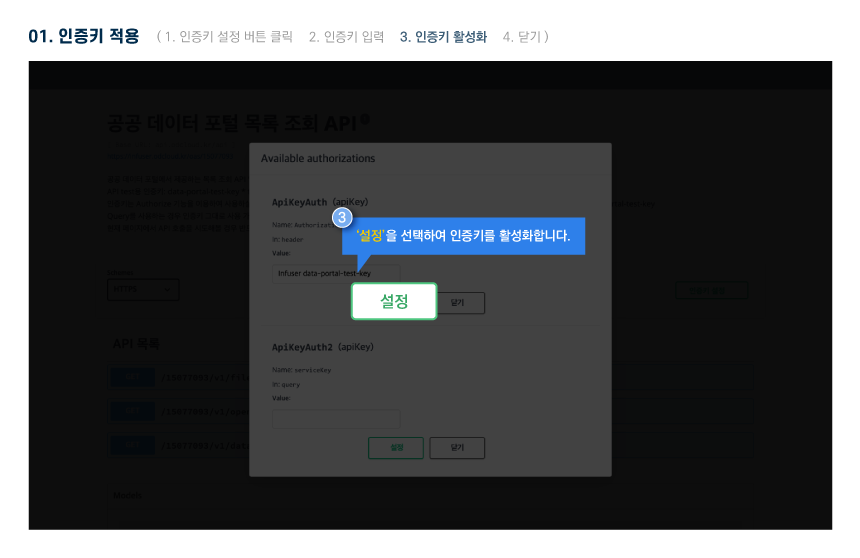
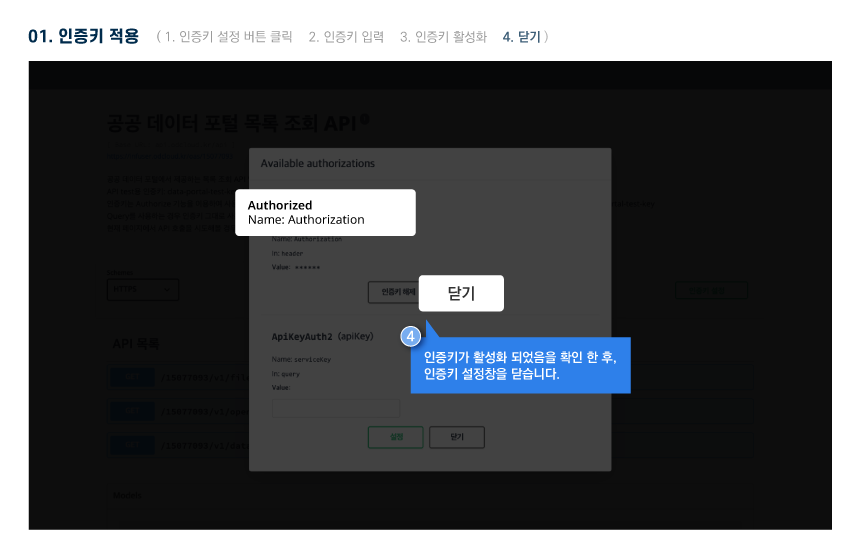
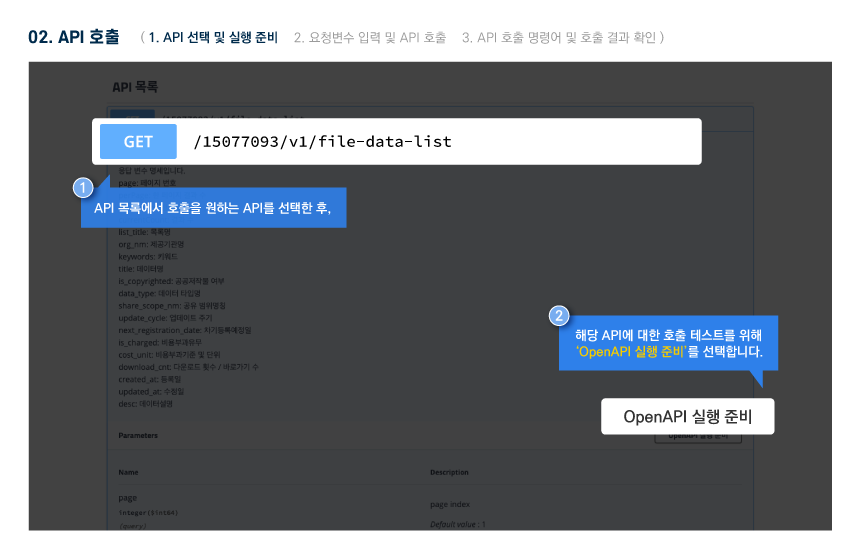
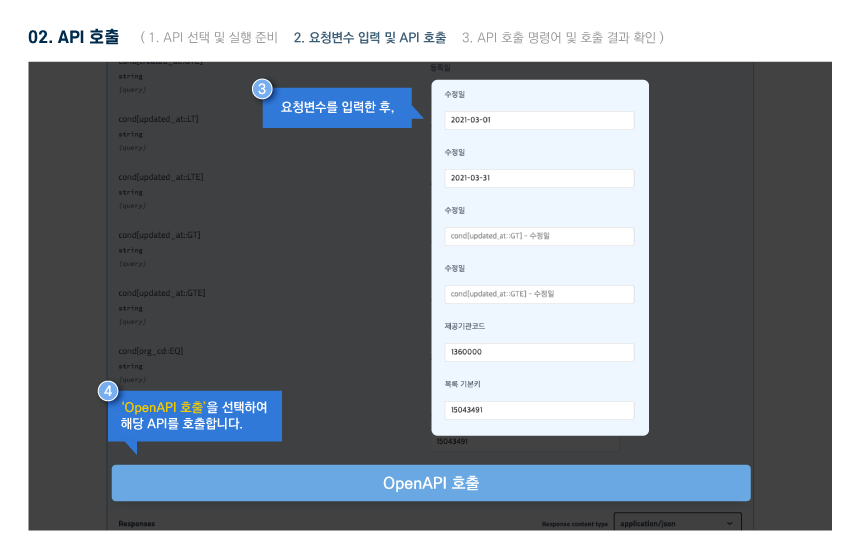
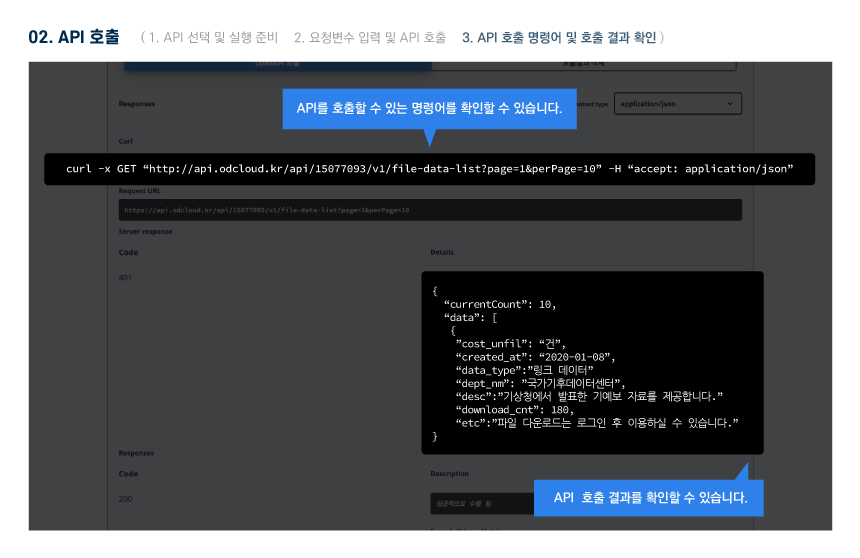
다른 사용자들이 활용한 데이터
로그인하셔서 다른 사용자들이 활용한 데이터를 추천받아 보세요
이 데이터와 유사한 데이터