데이터 상세
한국사회보장정보원_설문조사 목록
한국사회보장정보원에서 운영하고 있는 시스템의 만족도조사와 관련된 공공데이터입니다.
데이터 구성은 번호, 제목, 시작일자, 종료일자, 상태 항목으로 구성되어 있습니다.
이러한 공공데이터를 통해 다음과 같은 데이터분석, 연구 등의 활용이 가능합니다.
*단순 예시 사례이니, 참고바랍니다.
○사용자 세분화 분석
-텍스트 마이닝 및 감성 분석: 주관식 답변(예: "좋았던 점", "개선할 점")에 포함된 키워드와 감정을 분석하여 사용자들이 시스템에 대해 느끼는 긍정적, 부정적 감정의 원인을 파악할 수 있습니다.
-워드 클라우드: 주관식 답변에서 자주 언급되는 단어들을 시각화하여 사용자들이 가장 많이 이야기하는 주요 이슈를 한눈에 파악할 수 있습니다.
-클러스터링: 사용자들을 만족도 점수, 사용 패턴, 인구통계학적 특성 등에 따라 유사한 그룹으로 묶을 수 있습니다. 각 그룹의 특성을 분석하여 맞춤형 개선 전략을 수립할 수 있습니다. 예를 들어, 만족도가 낮은 그룹의 특성을 파악하여 그들이 겪는 문제에 집중할 수 있습니다.
데이터 구성은 번호, 제목, 시작일자, 종료일자, 상태 항목으로 구성되어 있습니다.
이러한 공공데이터를 통해 다음과 같은 데이터분석, 연구 등의 활용이 가능합니다.
*단순 예시 사례이니, 참고바랍니다.
○사용자 세분화 분석
-텍스트 마이닝 및 감성 분석: 주관식 답변(예: "좋았던 점", "개선할 점")에 포함된 키워드와 감정을 분석하여 사용자들이 시스템에 대해 느끼는 긍정적, 부정적 감정의 원인을 파악할 수 있습니다.
-워드 클라우드: 주관식 답변에서 자주 언급되는 단어들을 시각화하여 사용자들이 가장 많이 이야기하는 주요 이슈를 한눈에 파악할 수 있습니다.
-클러스터링: 사용자들을 만족도 점수, 사용 패턴, 인구통계학적 특성 등에 따라 유사한 그룹으로 묶을 수 있습니다. 각 그룹의 특성을 분석하여 맞춤형 개선 전략을 수립할 수 있습니다. 예를 들어, 만족도가 낮은 그룹의 특성을 파악하여 그들이 겪는 문제에 집중할 수 있습니다.
공공데이터활용지원센터는 공공데이터포털에 개방되는 3단계 이상의 오픈 포맷 파일데이터를 오픈 API(RestAPI 기반의 JSON/XML)로 자동변환하여 제공합니다.
오픈 API를 활용하기 위해서는 공공데이터포털 회원 가입 및 활용신청이 필요하며, 활용 관련 문의는 공공데이터활용지원센터로 연락주시기 바라며,
데이터 자체에 대한 문의는 아래 제공기관의 관리부서 전화번호로 연락주시기 바랍니다.
파일데이터는 로그인 없이 다운로드를 통해 이용하실 수 있습니다.
오픈 API를 활용하기 위해서는 공공데이터포털 회원 가입 및 활용신청이 필요하며, 활용 관련 문의는 공공데이터활용지원센터로 연락주시기 바라며,
데이터 자체에 대한 문의는 아래 제공기관의 관리부서 전화번호로 연락주시기 바랍니다.
파일데이터는 로그인 없이 다운로드를 통해 이용하실 수 있습니다.
다른 사용자들이 활용한 데이터
로그인하셔서 다른 사용자들이 활용한 데이터를 추천받아 보세요
파일데이터 정보
공공데이터활용지원센터는 공공데이터포털에 개방되는 3단계 이상의 오픈 포맷 파일데이터를 오픈 API(RestAPI 기반의 JSON/XML)로 자동변환하여 제공합니다.
오픈 API를 활용하기 위해서는 공공데이터포털 회원 가입 및 활용신청이 필요하며, 활용 관련 문의는 공공데이터활용지원센터로 연락주시기 바랍니다.
파일데이터는 로그인 없이 다운로드를 통해 이용하실 수 있습니다.
오픈 API를 활용하기 위해서는 공공데이터포털 회원 가입 및 활용신청이 필요하며, 활용 관련 문의는 공공데이터활용지원센터로 연락주시기 바랍니다.
파일데이터는 로그인 없이 다운로드를 통해 이용하실 수 있습니다.
다른 사용자들이 활용한 데이터
로그인하셔서 다른 사용자들이 활용한 데이터를 추천받아 보세요
오픈API 정보
활용 명세
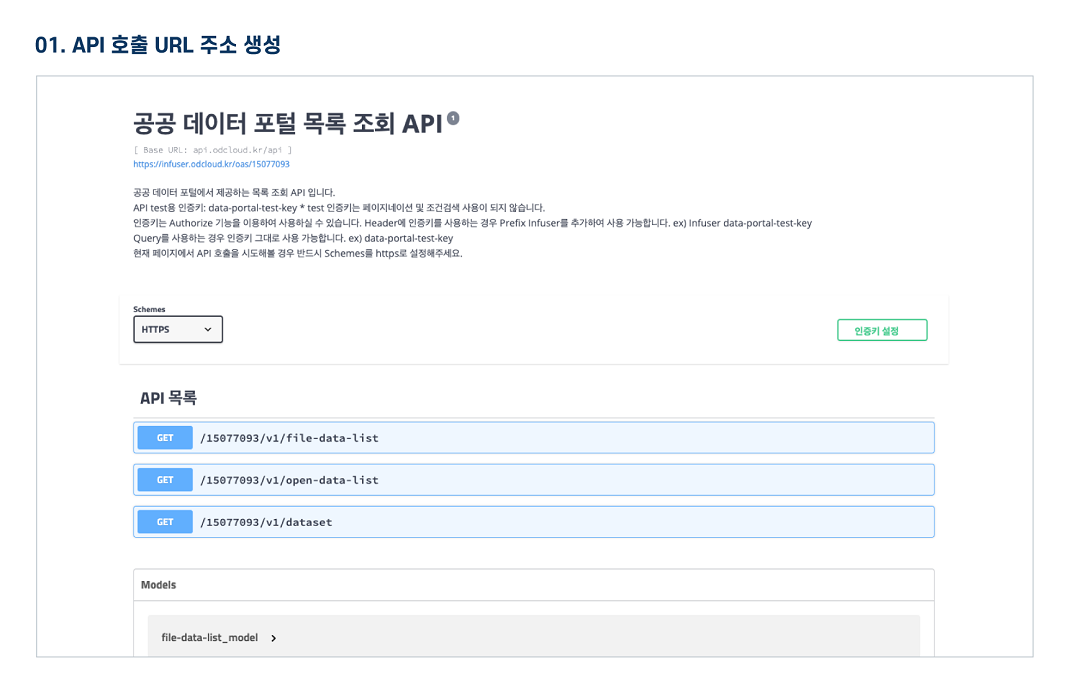
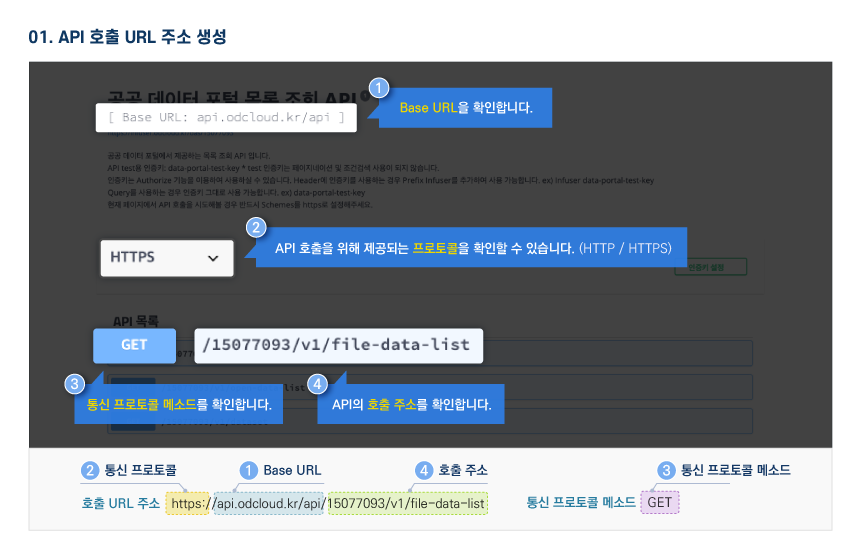
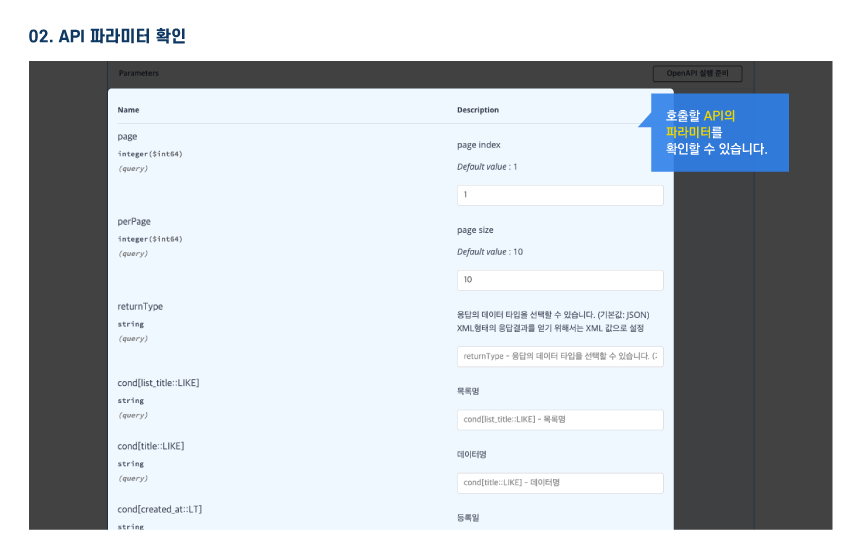

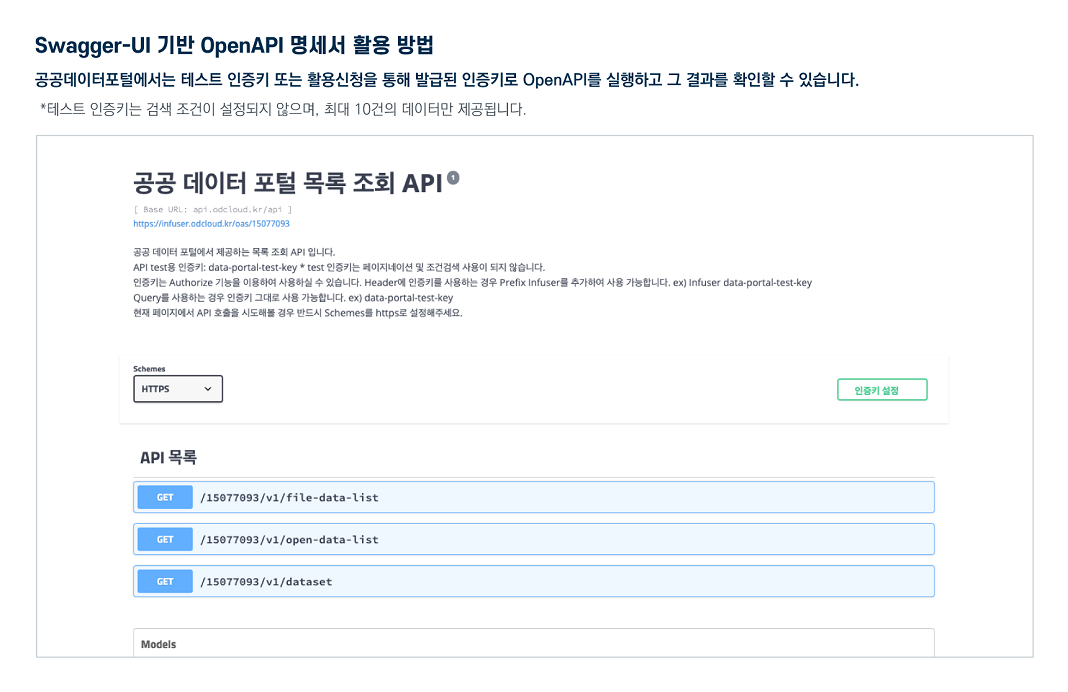
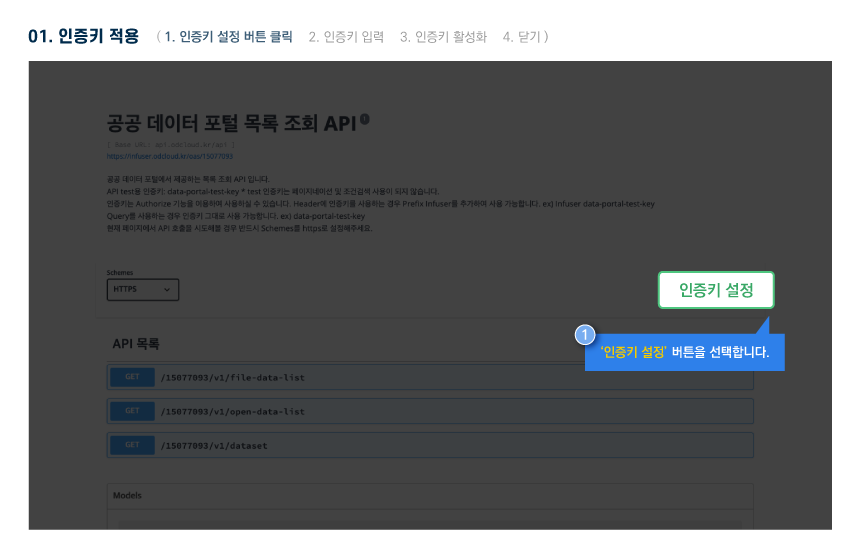
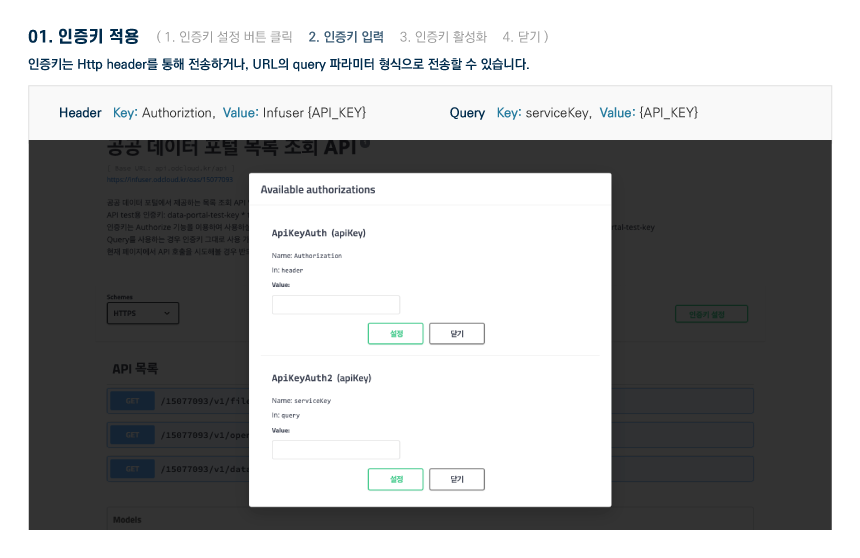
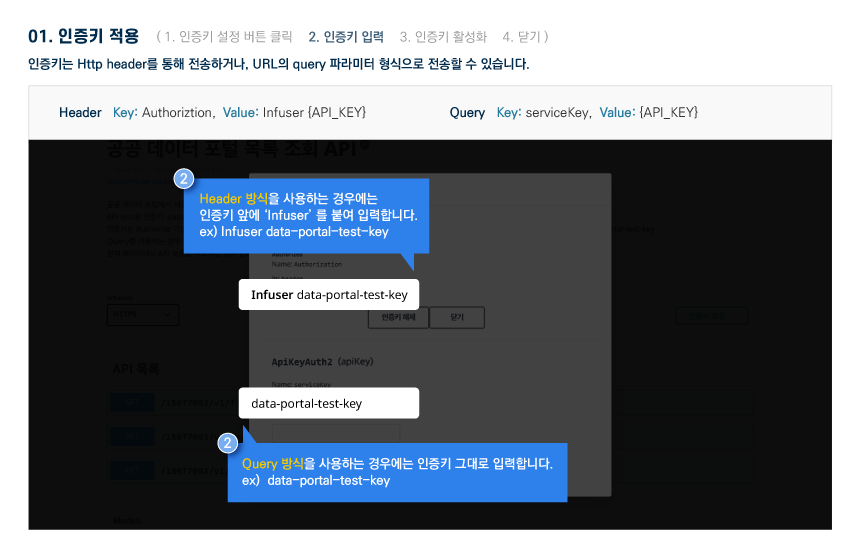
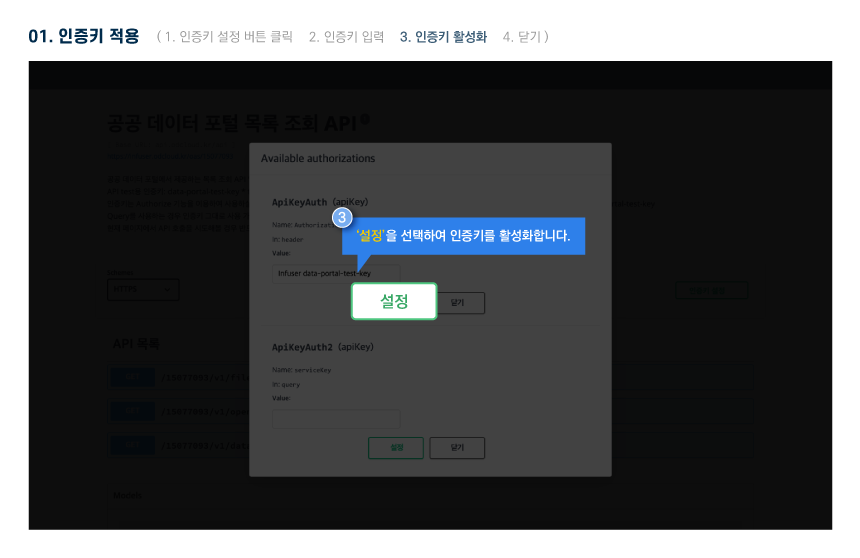
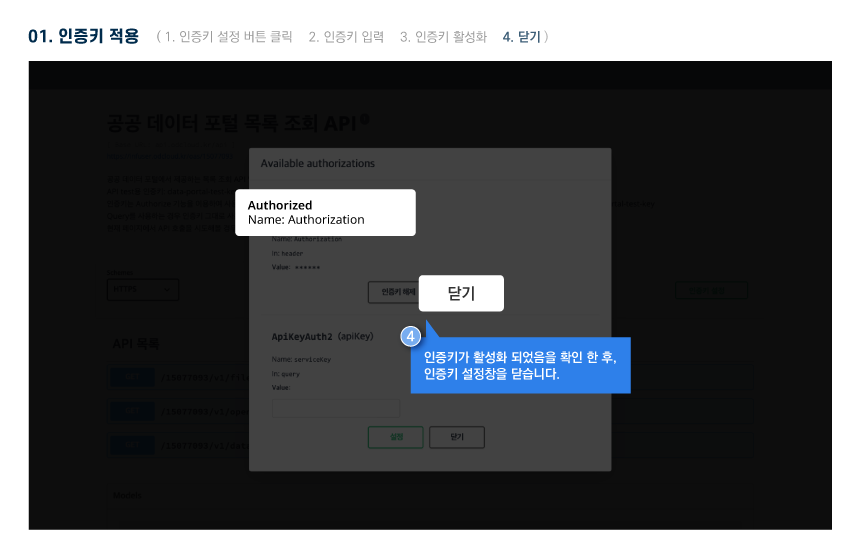
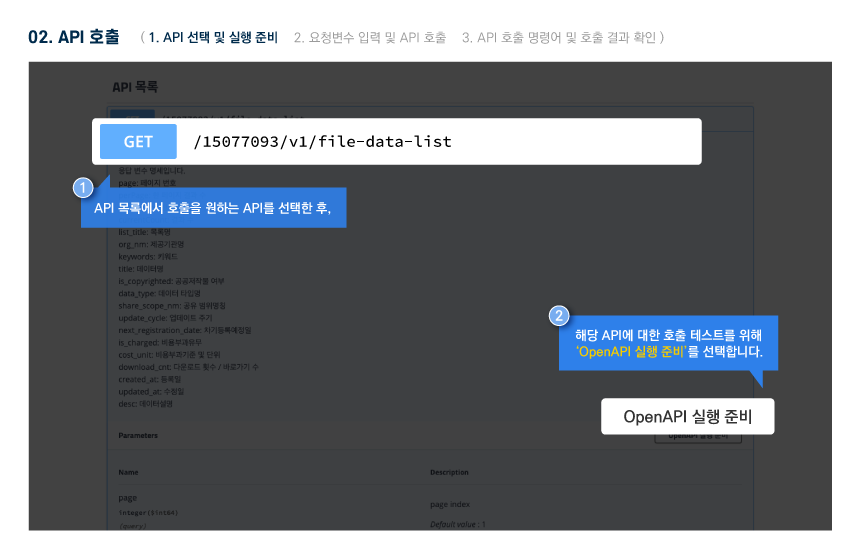
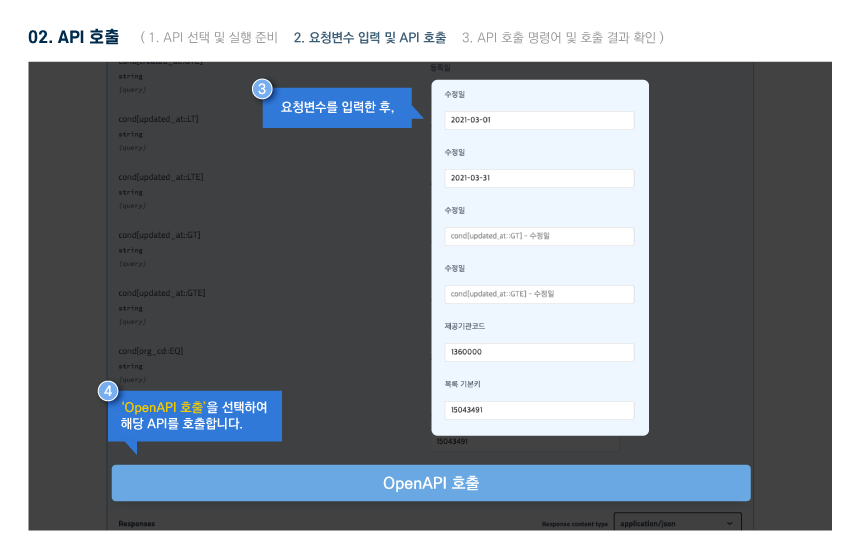
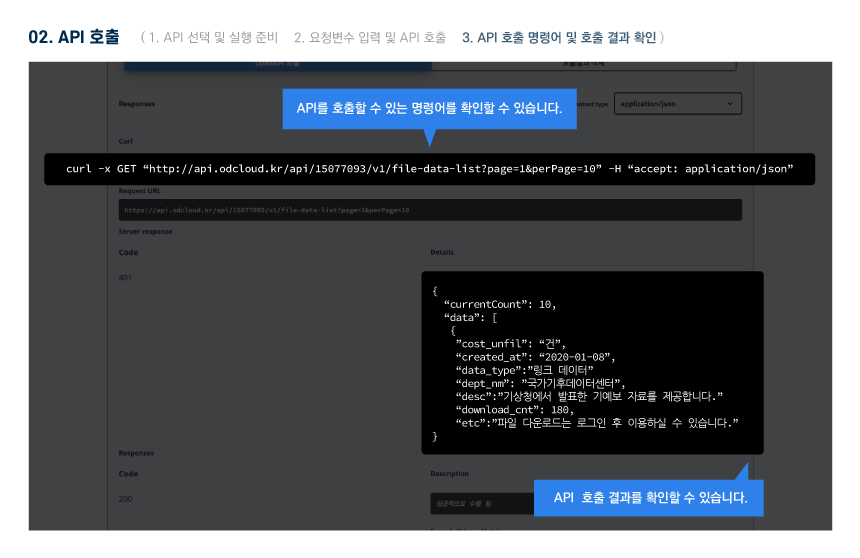
다른 사용자들이 활용한 데이터
로그인하셔서 다른 사용자들이 활용한 데이터를 추천받아 보세요
이 데이터와 유사한 데이터